This post shares some of the learnings from building ML practices at tech companies. Each organization is different, so take everything with a pinch of salt.
Business problems should be solved in the simplest way possible, but not simpler. The process of analyzing and modeling data is frequently complex since it requires interdisciplinary work, historical data (usually in large amounts), and specialized algorithmic knowledge to tackle open-ended problems that may not have a solution. As a result, model training should be used in cases where traditional business rules and domain expertise come short. Simple heuristics can go a long way, especially in issues never addressed before. Though there are common business problems and existing solutions, most ML features will go through an experimental phase due to quirks in the data and specifics in the problem.
Business features and ML
There’s no single way to separate ML (DS, AI, etc.) from other engineering work. Nevertheless, here are some ideas that can be used to identify problems best suited for ML:
- Unstructured data problems with existing ML solutions (ex: Face recognition, Voice to Text translation, Short Text Summarization).
- Unstructured data problems commonly solved by training ML models (Text classification, custom image classification).
- Problems commonly solved with statistical models (Uplift modeling, multi-armed bandits, survival analysis).
- Structured classification and regression problems commonly solved with ML (Churn detection, sales forecasts).
- Industry-specific problems with imperfect solutions (Tumor detection, bill summarization, weather forecasting).
Even if a problem matches one of the categories above, it may not be fixable at the moment. Some possible reasons are:
- The problem’s nature makes it hard to solve through existing methods (ex: predicting stocks, and weather).
- Business rules or domain expertise works sufficiently well.
- There’s no clear reason why a data-based approach may improve current performance.
- Not enough quality data available.
- Very low to no margin of error (autonomous weapons).
- Deep domain expertise is required and not available (Public Policy, Medical Imaging).
- Specialized technical knowledge is required and not available (Reinforcement Learning, Distributed Learning).
- The infrastructure required is not available or affordable (Large GPU training clusters, Large inference clusters).
Before starting ML development to build a business feature, here are some useful questions to ask:
- Why should this problem be solved with a data-based approach?
- What data could be used to solve this issue?
- Do we have the data to try to solve this issue?
- Can the data be trusted?
- When and how is the data updated?
- What is the process to get the required data?
- What family of models is best suited to solve this issue?
- How much data do I have for modeling/analysis?
- What metrics should I use?
- How is the data distribution changing over time?
- How does the existing research approach the problem?
ML Lifecycle Frameworks
The increased uncertainty in ML projects makes quick iteration and user validation even more relevant. There are multiple frameworks proposed to manage the Data Science and Machine Learning lifecycle. Though we won’t explain them in detail, some of them are:
Knowledge Discovery in Databases (KDD)

https://www.sciencedirect.com/topics/computer-science/knowledge-discovery-in-database
Cross Industry Standard Process for Data Mining (CRISP-DM)

https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
Team Data Science Process (TDSP)
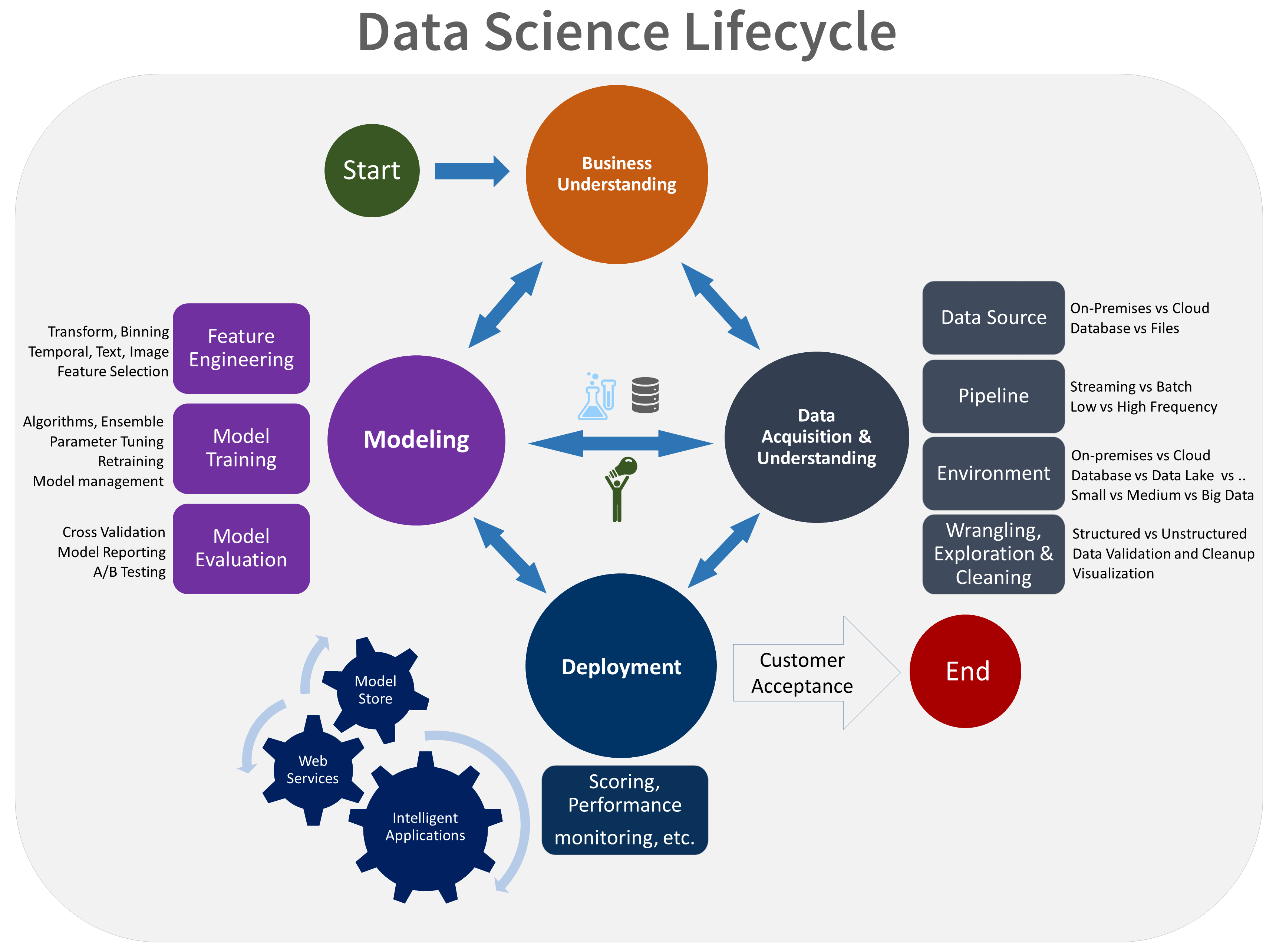
https://learn.microsoft.com/en-us/azure/architecture/data-science-process/overview
Common Patterns in ML Lifecycle Frameworks
- Business understanding is usually the starting point.
- Data analysis and transformations are very important.
- There’s always continual iteration between modeling and deployment.
- Metrics and evaluations enable improvements in the cycle.
ML Feature Development
Developing ML features can be divided into continual iterations of four steps, three required and one optional depending on the specific project:
- Experimentation
- Evaluation
- Deployment
- Integration
Some features will require additional work from external teams (DE, Web developers) to be used. Though it’s not the ML team’s direct responsibility, if it fails the feature won’t reach the final user. That’s why Integration is included as part of the cycle.
Iterating through this process as soon as possible allows us to gather user feedback and reduce uncertainty. However, minimal requirements are needed to develop ML safely and effectively.
Requirements before the initial iteration
- Business problem description
- Sample of input data
- Sample of labeled data (if required)
- Expected deployment pattern
- Expected integration plan
- Measurable success criteria
- Implemented baseline metrics (if possible)
- Defined usage metrics (with direct or indirect feedback)
- Defined model metrics
- First deployment threshold
- Final deployment threshold (proposed)
Requirements to close the initial iteration
- Deployment threshold met
- Replicable experimental code
- Basic deployment code
- Basic integration code (if required)
- Modular deployment/integration to allow quick model changes
- Usage metrics collection implemented
Requirements to close the final iteration
- Production-ready training and inference code with tests
- Final deployment metrics met
- Complete input data available
- Success metrics collection implemented (if required)
- Data drift metrics implemented
Though this may be the final part of an active ML development, as long as the model is in production some evaluation metrics should be required.
Common issues to avoid
- No integration resources are available for the project
- Very short projects with a single iteration