I had to take a short walk after seeing the OpenAI O3 launch and benchmark results. Since writing is thinking, here’s my attempt to understand why it had this big of an impact on me.
I use Language Models (LMs) everyday in my work and personal projects, and they are impressive. Up until Sonnet 3.5, they felt great for NLP tasks and System 1 (associative) thinking. I tried them a few times for planning or big refactors and was not impressed. You can learn more about System 1 and System 2 thinking here.
This opinion was reinforced by the performance on two benchmarks: ARC-AGI for solving unknown tasks and FrontierMath for exceedingly challenging math problems. Current LMs performance, even Sonnet 3.5 and O1, was lacking. O3 beat average human performance on ARC-AGI and made significant strides into FrontierMath.
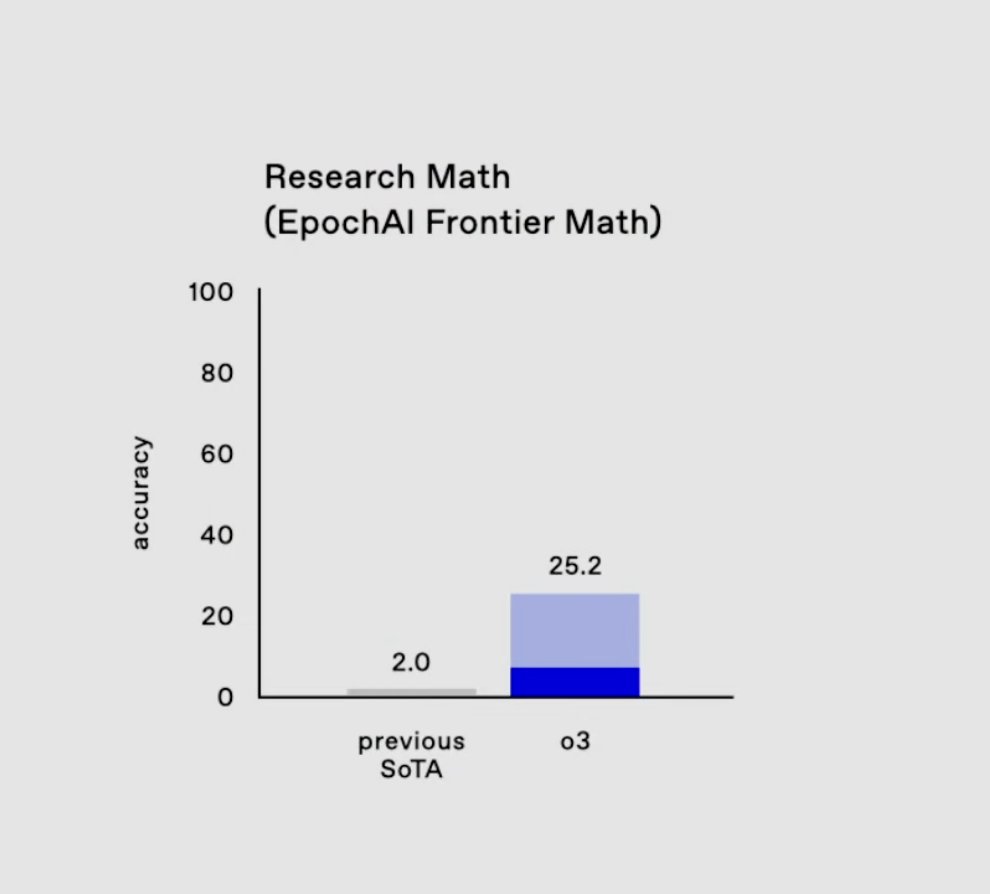
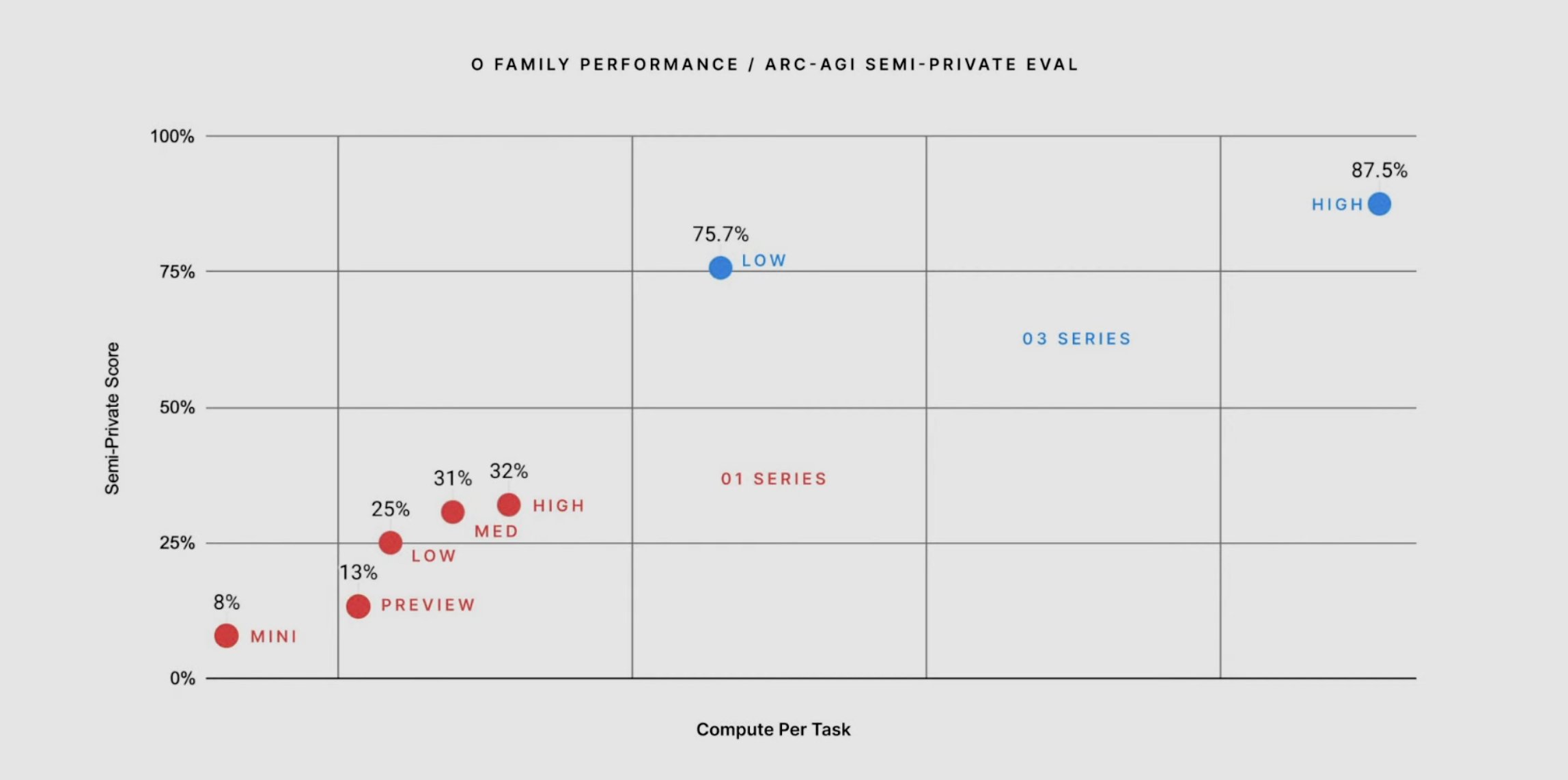
What is the secret ingredient? Some people say it’s just scaling O1 test time inference. Does it include MCTS, is it still mostly autoregression? I don’t know, but there is some gossip. If the results hold and generalize to other tasks, we may have reached human-level System 2 (logical) thinking. This unlocks a lot of knowledge work we humans usually do, moving AI beyond automating low complexity repetitive tasks. Who knows the exact impact on the economy, but a lot of everyday work would change, though it could take a while to get there.
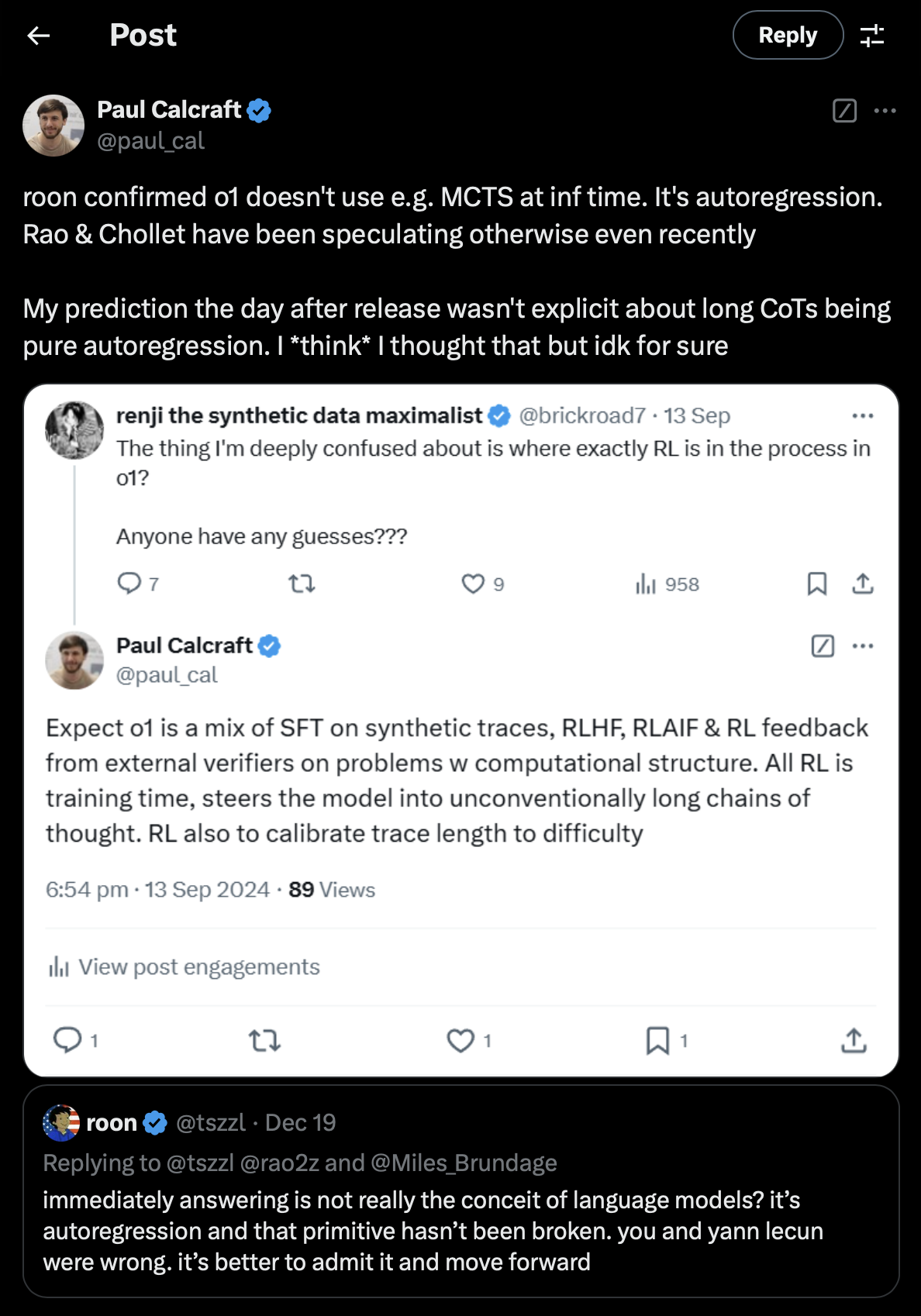
This doesn’t mean that AI will do everything humans do the way we do it. Do we spend the equivalent of thousands of dollars in compute solving ARC-AGI tasks? Maybe, but human thinking tends to be energy efficient, we don’t have time or resources to lose when a threat is nearby. Reducing compute costs will be key to making S2 thinking work for more people, and maybe we will take inspiration from human processes. If compute is the main bottleneck, I’m hopeful that improvements on hardware and architecture will make S2 thinking more accessible. We already can run GPT4 level inference in a home server.
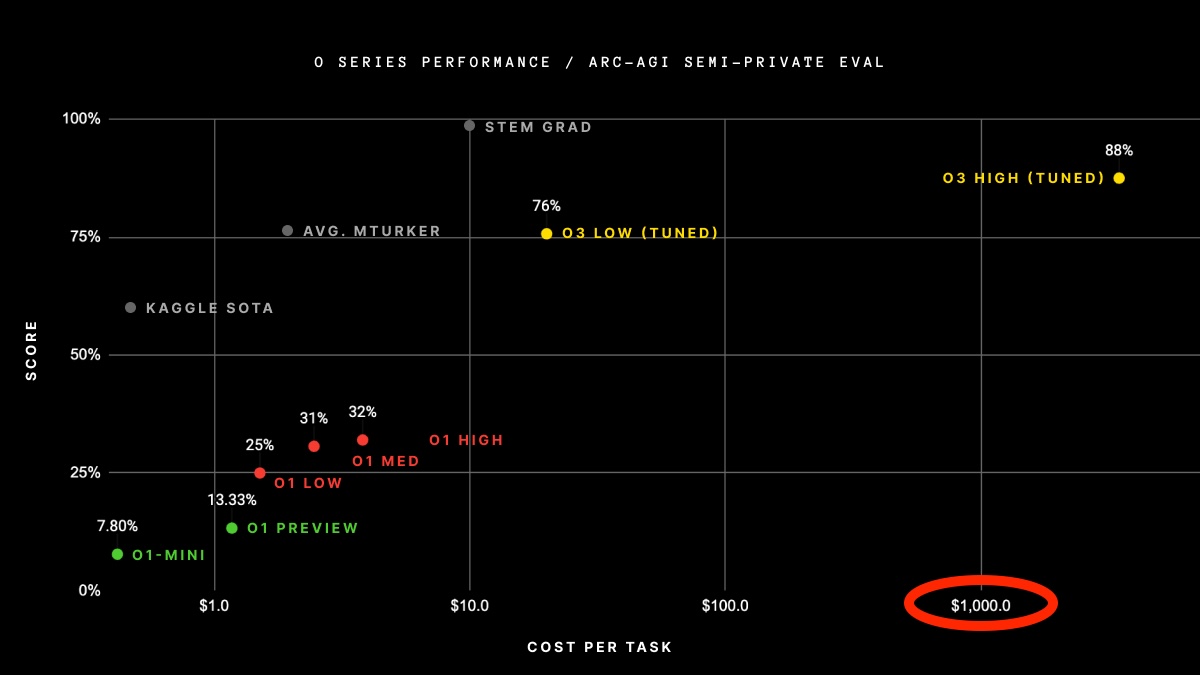
Long term memory, human level motor skills adaptation, and others have yet to be solved, but I wouldn’t bet on slowing decision making improvements in the long term. Even if AI eventually beats humans on most S2 tasks, there’s still value in human thinking. We may be greatly suited for subsets of problems where new LMs are not as good or efficient, and we may want to predict or understand human behavior for specific use cases.
Lastly, I’m still impressed by Sonnet 3.5 and it’s my daily driver. The responses sometimes feel qualitatively different than other LMs, specially around meta level behavior. Two of my favourite examples are identifying that is being tested and refusing to answer to repeated unreasonable messages. Anthropic work on Constitutional AI and Interpretability is great, and they have had the best publicly available model for a while. I wonder what they have in store.
As a fun bonus, here’s an example of current LMs answering “Who is more powerful than sun wu Kong in journey to the west?”, where to my passing knowledge GTP4o clearly fails, Sonnet 3.5 is close, and O3 is correct due to the reasoning chain.
